Coefficient of variation
In probability theory and statistics, the coefficient of variation (CV) is a normalized measure of dispersion of a probability distribution. It is defined as the ratio of the standard deviation 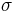 to the mean
to the mean  :
:
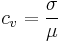
This is only defined for non-zero mean, and is most useful for variables that are always positive. It is also known as unitized risk or the variation coefficient. It is expressed as percentage.
The coefficient of variation should only be computed for data measured on a ratio scale. As an example, if a group of temperatures are analyzed, the standard deviation does not depend on whether the Kelvin or Celsius scale is used since an object that changes its temperature by 1 K also changes its temperature by 1 C. However the mean temperature of the data set would differ in each scale by an amount of 273 and thus the coefficient of variation would differ. So the coefficient of variation does not have any meaning for data on an interval scale.[1]
Standardized moments are similar ratios, 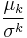 , which are also dimensionless and scale invariant. The variance-to-mean ratio,
, which are also dimensionless and scale invariant. The variance-to-mean ratio, 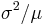 , is another similar ratio, but is not dimensionless, and hence not scale invariant.
, is another similar ratio, but is not dimensionless, and hence not scale invariant.
See Normalization (statistics) for further ratios.
In signal processing, particularly image processing, the reciprocal ratio 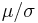 is referred to as the signal to noise ratio.
is referred to as the signal to noise ratio.
Contents |
Comparison to standard deviation
Advantages
The coefficient of variation is useful because the standard deviation of data must always be understood in the context of the mean of the data. The coefficient of variation is a dimensionless number. So when comparing between data sets with different units or widely different means, one should use the coefficient of variation for comparison instead of the standard deviation.
Disadvantages
- When the mean value is near zero, the coefficient of variation is sensitive to small changes in the mean, limiting its usefulness.
- Unlike the standard deviation, it cannot be used to construct confidence intervals for the mean.
Applications
The coefficient of variation is also common in applied probability fields such as renewal theory, queueing theory, and reliability theory. In these fields, the exponential distribution is often more important than the normal distribution. The standard deviation of an exponential distribution is equal to its mean, so its coefficient of variation is equal to 1. Distributions with CV < 1 (such as an Erlang distribution) are considered low-variance, while those with CV > 1 (such as a hyper-exponential distribution) are considered high-variance. Some formulas in these fields are expressed using the squared coefficient of variation, often abbreviated SCV. In modeling, a variation of the CV is the CV(RMSD). Essentially the CV(RMSD) replaces the standard deviation term with the Root Mean Square Deviation (RMSD).
Distribution
Under weak conditions on the sample distribution, the probability distribution of the coefficient of variation is known. In fact, it has been determined by Hendricks and Robey [2]. This is useful, for instance, in the construction of hypothesis tests or confidence intervals.
See also
- Normalization (statistics)
Similar ratios
- Standardized moment,
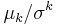
- Variance-to-mean ratio,
- Fano factor,
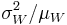 (windowed VMR)
(windowed VMR) - Signal to noise ratio, (in signal processing)
External links
References
- ↑ "What is the difference between ordinal, interval and ratio variables? Why should I care?". GraphPad Software Inc. http://www.graphpad.com/faq/viewfaq.cfm?faq=1089. Retrieved 2008-02-22.
- ↑ The Sampling Distribution of the Coefficient of Variation, Walter A. Hendricks and Kate W. Robey, Ann. Math. Statist. Volume 7, Number 3 (1936), 129-132.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||